朔州日本云服务器维护应急恢复演练流程与演练频率建议
1.
演练目标与适用范围
目标:保证日本云服务器在常见故障(主机宕机、网络中断、磁盘损坏、应用异常)下能在规定RTO/RPO内恢复。
适用范围:适用于云主机(含浮动IP/弹性IP)、云块存储与数据库实例,适合朔州运维团队与第三方运维服务协作演练。
2.
演练前准备:清单与权限
清单:确认主机清单、浮动IP、控制台访问、快照权限、备份位置、监控报警触达人员;列出恢复联系人与时间窗口。
权限:确保演练人员拥有SSH root/sudo、云控制台API/CLI权限(创建快照、挂载卷、修改浮动IP)、DNS管理权限(TTL可临时降低)。
3.
演练工具与脚本准备
工具:准备ssh、rsync、scp、mysqldump或pg_dump、systemctl、ip route、iptables、nc、curl等工具;准备日志采集与告警回放工具。
脚本:编写并测试恢复脚本,包括:1) 快照创建/挂载脚本;2) 数据库导入脚本(示例:mysqldump -u root -pPWD db > /tmp/db.sql);3) 浮动IP切换脚本(调用云CLI或修改路由);4) 服务启动脚本(systemctl start myapp)。
4.
故障模拟:如何安全触发
步骤一(网络):在非生产时间对目标主机防火墙临时drop外网流量,示例:iptables -I OUTPUT -p tcp --dport 80 -j DROP,记录影响范围并立即可回滚。
步骤二(主机宕机):先在备机上完成切换准备,再执行systemctl stop 服务或利用云控制台先暂停实例,确保能通过快照/恢复到备机。
5.
恢复流程:从故障到服务可用的具体操作
步骤一(确认故障):通过监控与ssh尝试登录,判断是网络、主机OS无响应或磁盘故障,记录时间点与日志(/var/log/messages, journalctl)。
步骤二(数据恢复):如果本地磁盘损坏,使用最近快照挂载到恢复主机:云CLI示例(AWS)aws ec2 create-snapshot/attach-volume,或rsync恢复:rsync -avz /backup/www/ /var/www/。
步骤三(应用切换):在备机上恢复配置、修改DNS/浮动IP。浮动IP切换示例(假设云CLI):cloud-cli floating-ip assign --ip X.X.X.X --instance-id i-xxxx。
步骤四(数据库恢复):执行mysql导入示例:mysql -u root -pPWD db < /tmp/db.sql,检查表一致性与binlog位置,若需要做增量恢复按binlog顺序apply。
6.
验证与回滚:确认服务健康与回退流程
验证项:1)页面与API连通性curl -I http://app.example.com;2)业务关键路径(登录、下单等)自动化脚本跑通;3)日志无异常。
回滚策略:若恢复后发现数据不一致或性能问题,使用备份快照还原至故障前实例或将流量回切至原主机(在能恢复时),并记录回滚理由与时间。
7.
演练频率与分级建议
频率:建议季度进行一次全面演练(包含数据恢复与浮动IP切换),月度进行一次局部(配置/服务重启)演练,关键更新或迁移前必须进行专项演练。
分级:按影响范围分为内部演练(不影响外部流量)、控制台演练(通过云控制台动作)和全链路演练(真实切换DNS/浮动IP并通知客户)。每次演练后必须产出演练报告与改进项。
8.
问:演练过程中发现恢复失败或数据损坏怎么办?
答:立刻停止影响范围扩展,启用回滚计划:1) 使用最近快照恢复到备机;2) 将流量回切到既有备份实例;3) 根据业务优先级决定是否接受部分数据损失(RPO)并通知相关方;4) 演练结束后进行根因分析并更新备份频率与检查点。
9.
问:针对日本云服务器有什么特殊注意事项?
答:注意网络延时与跨境带宽限制,提前验证跨区域快照与镜像的可用性;检查时区与法务合规(数据驻留要求);浮动IP或弹性IP在不同机房的行为差异需事先测试。
10.
问:演练所需资源与人员配备建议是什么?
答:建议每次演练至少包含:演练指挥1人、主机工程师2人、数据库工程师1人、网络/安全1人、业务方代表1人;准备好应急联系方式、演练脚本、回滚脚本与集中日志以便事后复盘。

-

VPS日本玻璃女神:解析这个独特而强大的组合
VPS日本玻璃女神:解析这个独特而强大的组合 在当今互联网时代,VPS(Virtual Private Server)已经成为许多网站和应用程序的首选托管方案。日本作为一个高度发达的科技国家,拥有先进的通信和数据中心设施,因此成为了许多人选择的VPS托管地之一。本文将深入探讨VPS日本玻璃女神这个独特而强大的组合。2025年3月13日 -
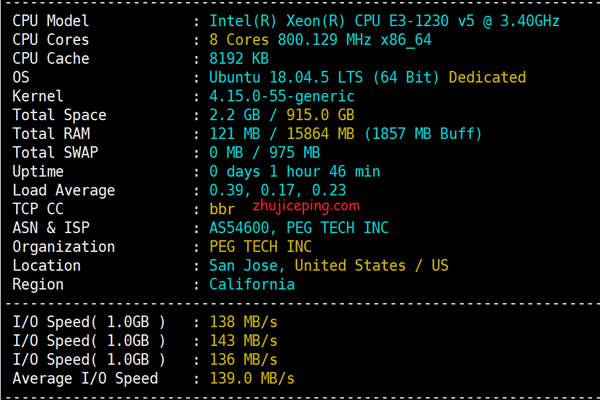
租用日本VPS的5大理由及注意事项
在当今数字化时代,越来越多的企业和个人选择租用日本VPS(虚拟专用服务器)来满足他们的网络需求。日本VPS以其高效的性能和稳定的网络环境而受到广泛欢迎。本文将探讨租用日本VPS的五大理由及相关注意事项,帮助读者做出明智的选择。 为什么选择日本VPS? 选择日本VPS的原因有很多。首先,日本的网络基础设施极其发达,能够提供高速、稳定的网络连接,2025年9月8日 -

日本VPS查看IP,发现是美国
日本VPS查看IP,发现是美国 近年来,随着互联网的快速发展,虚拟私有服务器(VPS)的使用越来越广泛。许多人选择在日本购买VPS,以便在互联网上进行各种活动。然而,有时候他们会发现自己的日本VPS的IP地址显示为美国。本文将探讨这一现象的原因以及对用户的影响。 IP地址是互联网上设备的唯一标识符。它可以用来确定设备的地理位置2025年3月29日 -

VPS日本机房ping:快速、稳定的选择
VPS日本机房ping:快速、稳定的选择 对于需要连接到日本网络的用户来说,选择一个快速、稳定的VPS机房是非常重要的。本文将介绍日本机房ping的重要性以及为什么选择日本机房ping作为最佳选择。 在选择VPS机房时,ping值是一个重要的参考指标。Pi2025年5月2日 -

日本服务器性能评测,光算云行不行
日本服务器因其优越的网络环境和高效的服务质量,吸引了众多用户的关注。本文将对日本服务器,尤其是光算云的性能进行详尽评测,并提供实际操作步骤指南,帮助用户更好地理解和使用服务器。 1. 什么是光算云? 光算云是一种基于云计算技术的服务器服务,主要提供高性能计算资源和灵活的使用模式。其主要特点包括高可用性、可扩展性和便捷的管2025年9月30日 -

如何选择适合的日本云服务器品牌与服务
选择日本云服务器的三大精华 在当今数字化时代,选择合适的日本云服务器品牌与服务至关重要。无论是企业网站、电子商务平台还是个人博客,选择一个合适的云服务器都能大大提高网站的性能和安全性。以下是三个关键点,帮助您更好地做出选择: 性能与稳定性的重要性 价格与性价比的考量 客户支持的质量及响应时间 在选择日本云服务器时,2025年9月29日 -

阿里云转日本VPS:快速、稳定的选择
阿里云转日本VPS:快速、稳定的选择 阿里云转日本VPS是一种快速、稳定的选择,适合个人和企业用户。它提供了高性能的服务器,具有出色的性价比。相比其他服务提供商,阿里云转日本VPS具有以下优势: 1. 快速响应时间 阿里云转日本VPS具备出色的网络连接和数据传输速度,确保用户可以快速访问和传输数据。这对于需要频繁与日本服务器进行通2025年2月28日 -
电商与媒体业务如何在日本的服务器云上优化成本与响应速度
1. 前言:在日本部署为何要重视成本与响应 · 日本市场对页面加载时间敏感,首屏延迟每增加100ms转化率可能下降约0.5%-1%。 · 电商与媒体对并发与带宽需求大,峰值流量决定基础设施成本。 · 服务器位置直接影响用户侧平均延迟(东京到大阪典型8-12ms)。 · 合理选择VPS/云主机与CDN能显著降低带宽与原站压力。 · DDoS防御是运2026年4月24日 -

使用日本VPS OpenVPN保障您的网络安全
在数字化时代,网络安全已经成为每个互联网用户必须关注的重要问题。通过使用日本VPS搭配OpenVPN技术,您可以有效提升个人和企业的网络安全性。值得一提的是,德讯电讯在这一领域提供了卓越的服务,助您轻松实现安全上网。 何为VPS与OpenVPN VPS(虚拟专用服务器)是一种将服务器虚拟化后为用户提供的独立环境。与传统的共享主机相比,VP2025年9月27日